

У цій статті ми крок за кроком розглянемо установку Microsoft SQL Server 2019 з описом всіх опцій, компонентів, актуальних рекомендацій і best practice.
MS SQL Server це лідируюча РСУБД (Реляційна система управління базами даних) а також головний конкурент Oracle Database в корпоративному сегменті. У СНД MSSQL найчастіше застосовується для власних розробок прикладного ПО і для 1С.
зміст:
- Редакції MS SQL Server 2019
- Особливості ліцензування SQL Server
- Початок установки SQL Server
- Додаткові параметри оновлення SQL Server при установці
- Тип інсталяції SQL Server
- Компоненти SQL Server 2019: для чого потрібні, які потрібно встановити
- Налаштування іменування примірника SQL Server
- Налаштування параметрів служб SQL Server, кодування
- Налаштування Database Engine в SQL Server
Редакції MS SQL Server 2019
Всього є 5 випусків (редакцій) MSSQL 2019:
- Express є безкоштовною для використання редакцією. Функціонал досить обмежений, найвідчутніше обмеження експрес версії - максимальний розмір бази 10 ГБ. Ця редакція підійде для невеликих проектів, наприклад, студентських робіт або для навчання SQL / T-SQL.
- Standard це повноцінна платна редакція, але багатьох функцій все ще немає. Максимальний об'єм оперативної пам'яті, який зможе використовувати SQL Server - 128 ГБ, також відсутні групи доступності AlwaysOn і інші компоненти. Standard призначений для додатків в невеликих організаціях.
- Enterprise включає в себе всі можливі функції і компоненти, ніяких обмежень немає. Корпоративна редакція зазвичай використовується великими корпораціями або компаніями, яким необхідний функціонал цієї версії.
- Developer редакція так само як і Enterprise не має ніяких обмежень і її можна використовувати безкоштовно, але вона може використовуватися тільки для розробки і тестування додатків.
- Web редакція майже нічим не відрізняється від standard, крім як сильнішими обмеженнями в функціоналі і відповідно більш низької вартості ліцензування.
Особливості ліцензування SQL Server
MS SQL Server ліцензується по 2 моделям:
- PER CORE - ліцензує MSSQL по ядрах сервера
- SERVER + CAL - ліцензія цілком на сервер і на кожного користувача, який буде працювати з сервером
Enterprise редакція може бути ліцензована тільки за типом PER CORE
Також в MSSQL Server 2019 з'явилася нова можливість для ліцензування контейнерів, віртуальних машин і Big Data Clusters.
Більш детальна інформація по ліцензування SQL Server представлена в окремій статті.Початок установки SQL Server
У цій статті ми будемо встановлювати MS SQL Server 2019 Enterprise Edition на Windows Server 2019.
Примітка. У SQL Server 2019 з'явилася повноцінна підтримка Linux, а відповідно Docker і Kubernetes.- Скачайте і розпакуйте інсталяційний образ SQL Server 2019. Запустіть setup.exe;
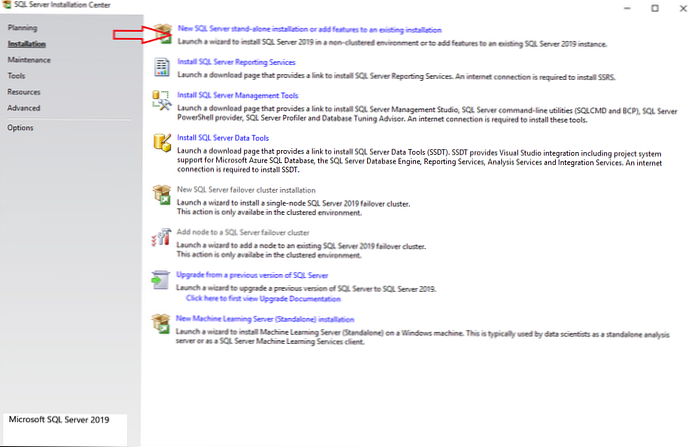
- Так як в цій статті ми будемо встановлювати звичайний ізольований екземпляр, у вкладці Installation виберіть "New SQL Server stand-alone installation".
В інсталятор SQL Server можна виконати багато інших дій: відновити старий екземпляр, полагодити зламаний і деякі інші речі.
Додаткові параметри оновлення SQL Server при установці
На цьому кроці ви можете включити пошук оновлень через Windows Update. Включати цю опцію чи ні, вирішувати вам. Все залежить від вашої планування оновлень і від вимог до відмовостійкості сервера. Якщо у вас немає чіткого плану оновлень ваших серверів, краще залиште цей параметр увімкненим.
На цьому кроці ви можете побачити таку помилку:Error 0x80244022: Exception from HRESULT: 0x80244022 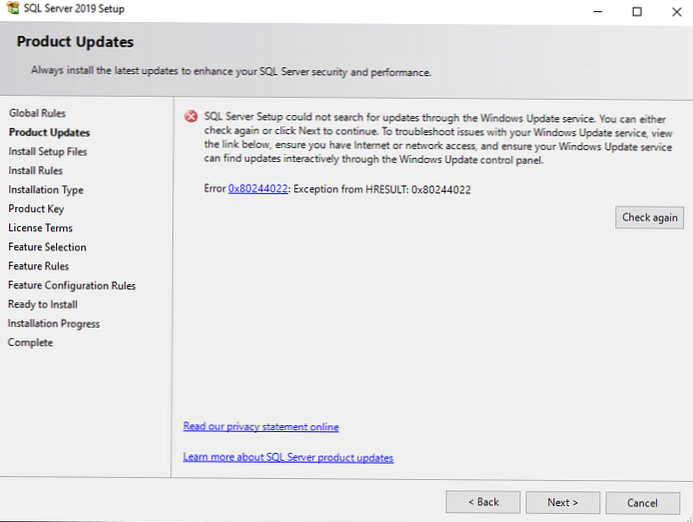
Вона пов'язана з проблемами зі службою Windows Update. Методи рішення описані тут https://winitpro.ru/index.php/2017/08/10/oshibka-0x80244022-i-problema-ostanovki-wsuspool/
натисніть Next.
крок Install Setup Files відбудеться автоматично. Він підготує файли для установки.
Install Rules так само пройде автоматично, якщо установник не виявить проблем, які необхідно вирішити перед установкою MSSQL (наприклад, перезавантажити комп'ютер або несумісність вашої версії Windows з версією SQL Server).
Тип інсталяції SQL Server
На цьому кроці ви можете вибрати установку нового екземпляра або додавання функціоналу в уже встановлений екземпляр. У нашому випадку вибираємо "Perform a new installation". 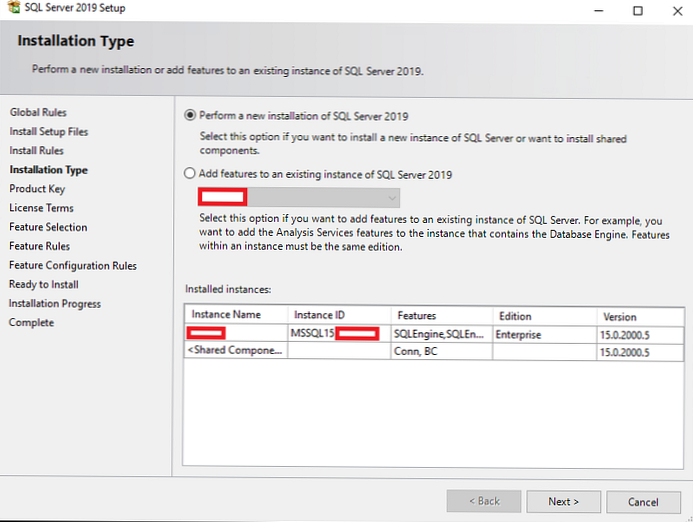
Тепер потрібно ввести ключ продукту. Якщо немає ключа, вибирайте Free edition (наприклад, Developer), але майте на увазі, що з редакцією Developer ви маєте право тільки розробляти і тестувати ПЗ, але не використовувати сервер у продуктивній середовищі. 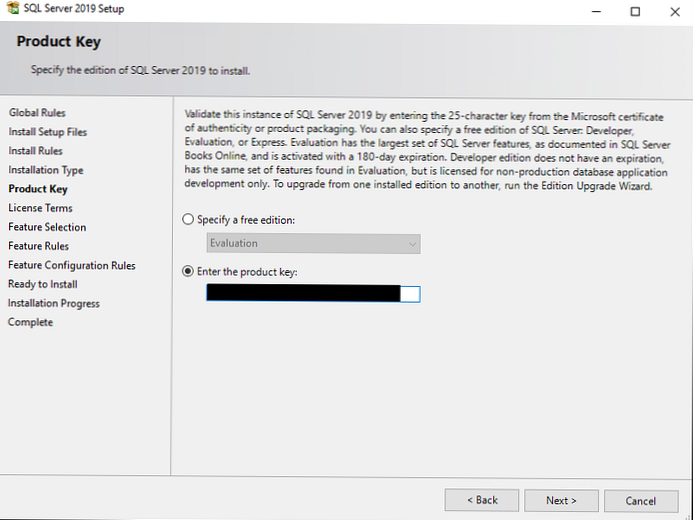
на кроці License Terms приймаємо ліцензійну угоду.
Компоненти SQL Server 2019: для чого потрібні, які потрібно встановити
На цьому етапі вам пропонують встановити різні компоненти SQL Server. Пройдемося по ним докладніше, подивимося які потрібно ставити в різних ситуаціях:
- Database Engine Services - це основний двигун SQL Server. Обов'язковий до установки.
- SQL Server Replication - служби реплікації. Компонент досить часто використовуються, тому якщо ви не впевнені чи потрібні вони вам, то краще відзначайте для установки.
- Machine Learning Services and Language Extensions - служби для виконання R / Python / Java коду в контексті SQL Server. Необхідно, якщо ви збираєтеся займатися Machine Learning.
- Full-Text and Semantic Extractions for Search - компонент необхідний, якщо вам потрібна повнотекстова технологія пошуку або семантичний пошук в документах (наприклад docx). У разі семантичного пошуку по документам, вам також знадобитися FILESTREAM, про нього нижче.
- Data Quality Services - служби для корекції та валідації даних. Якщо ви не впевнені чи потрібен вам DQS, то краще не встановлюйте його.
- PolyBase Query Service For External Data - технологія для доступу до зовнішніх даних, наприклад на іншому SQL Server або в Oracle Database. Java connector for HDFS data sources ставитися до PolyBase технології і потрібен у разі якщо ви хочете працювати з HDFS технологією.
- Analysis Services - також відомий як SSAS. Технологія для бізнес-звітів (BI) та роботи з OLAP. Використовується в великих компаніях для звітності.
Далі переходимо до списку Shared Features (функцій, що поширюються на весь сервер, а не на конкретний екземпляр).
- Machine Learning Server (Standalone) - те ж саме що і Machine Learning Services and Language Extensions, але з можливістю установки без самого движка SQL Server.
- Data Quality Client - те ж саме що і DQS, тільки standalone.
- Client Tools Connectivity - бібліотеки ODBC, OLE DB і деякі інші. Рекомендується ставити обов'язково.
- Integration Services - служби інтеграції даних, відомі також як SSIS. Технологія для ETL (Extract, Transform, Load) даних. SSIS потрібні, якщо ви хочете автоматизувати імпорт даних і змінювати їх в процесі імпорту. Scale Out Master / Worker потрібні для масштабування роботи SSIS. Якщо ви не впевнені чи потрібні вони вам, щось не відзначайте їх.
- Client Tools Backwards Compatibility - застарілі DMV і системні процедури. рекомендую ставити.
- Client Tools SDK - пакет з ресурсами для розробників. Можна не ставити, якщо не впевнені, чи потрібен він вам.
- Distributed Replay Controller / Client - повторюють і покращують функціонал SQL Server Profiler. Служби Distributed Replay потрібні для моделювання навантаження і для різного роду тестування продуктивності.
- SQL Client Connectivity SDK - ODBC / OLE DB SDK для розробників.
- Master Data Services - компонент з Microsoft Power BI. Потрібен для аналізу, валідації, інтеграції та корекції даних.
Деякі з цих компонентів (наприклад, Java connector for HDFS data sources) можуть бути відсутні в більш старих версіях SQL Server.
Трохи нижче, на цьому ж кроці, ви можете вказати директорію для файлів SQL Server'a. Якщо у вас немає вагомих причин змінювати її, то залиште стандартну (C: \ Program Files \ Microsoft SQL Server \).
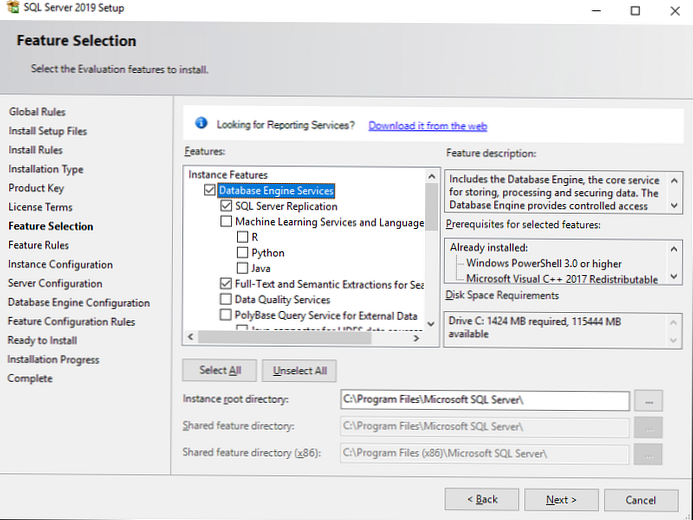
Після того як ви вибрали потрібні вам компоненти MSSQL, інсталятор перевіряє сумісність компонентів з вашою системою, і, якщо проблем немає, цей крок пройде автоматично.
Налаштування іменування примірника SQL Server
Ви можете залишити параметр Default Instance, в такому випадку ім'я вашого примірника буде MSSQLSERVER. При виборі Named Instance ви самі вказуєте ім'я екземпляра SQL Server. У моєму випадку я назву екземпляр DEV. Instance ID рекомендується ставити такий же, як і ім'я екземпляра, щоб уникнути плутанини.
У Installed instances відображаються встановлені на сервері екземпляри MSSQL, у мене вже є один.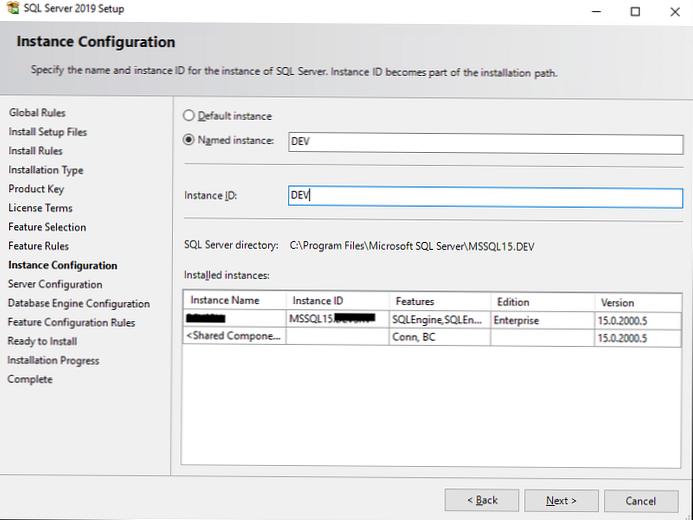
Налаштування параметрів служб SQL Server, кодування
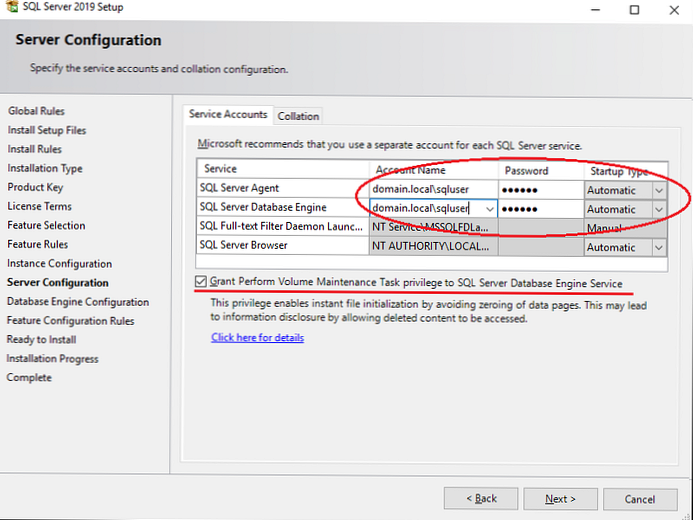
У вкладці Service Accounts вкажіть акаунти з-під яких працюватимуть служби SQL Server на хості. Доброю практикою вважається використання MSA (Managed Service Accounts) і gMSA (Group Managed Service Accounts) технологій, як найнадійніших в плані безпеки. Я буду використовувати звичайний доменний аккаунт.
виставте у SQL Server Agent поле Startup Type в Automatic, інакше агент доведеться запускати вручну.
Також починаючи з SQL Server 2016 з'явилася можливість виставляти параметр IFI (Instant File Initialization) при установці сервера. В інсталятор він називається "Grant Perform Volume Maintenance Task privilege to SQL Server Database Engine". Його включення означає, що старі дані не будуть записуватись нулями при:
- Створення бази даних;
- Додаванні даних в файли даних або лог файли;
- Збільшення розміру існуючих файлів (включаючи операції авто збільшення);
- Відновленні бази даних / файлової групи.
Це прискорює процес ініціалізації файлів, але зменшує безпеку, потім що старі дані не затираються нулями, тому стара інформація, яка містилася в цих файлах, може бути часткова доступна.
Рекомендую включати цей параметр, якщо небезпека витоку даних несуттєва.
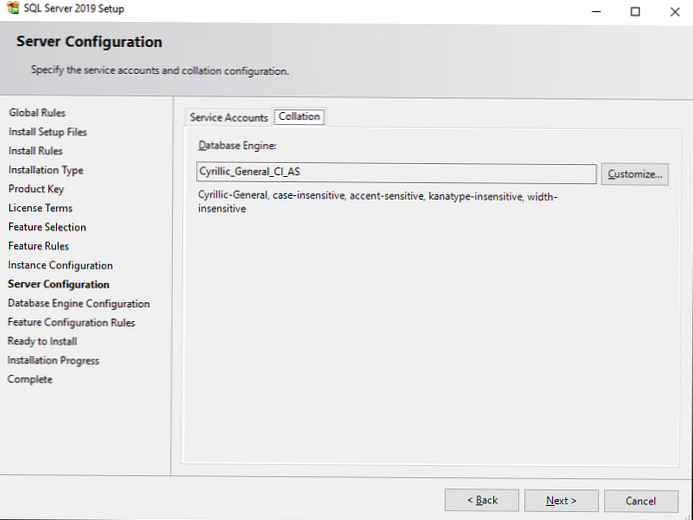
На наступному кроці ви повинні вибрати Collation.
Грубо кажучи, Collation це настройка кодування SQL Server. Цей параметр встановлює кодування сторінок, правила сортування, кодування для char / varchar і інші мовні настройки.
При установці сервера ви вибираєте Collation для всього SQL Server. Після установки можна буде поміняти цей параметр, але зробити це буде непросто, тому потрібно відразу вибрати відповідний для ваших завдань Collation.
Для СНД рекомендується вибирати Cyrillic_General_CI_AS. Якщо дані будуть тільки англійською, можна вибирати SQL_Latin1_General_CP1_CI_AS.
Якщо ви плануєте використовувати SQL Server в бойових умовах, ознайомтеся з документацією щодо вибору Collation, так як це важливий параметр, хоч він і може бути заданий для конкретної бази даних.
Налаштування Database Engine в SQL Server
на кроці Database Engine Configuration доступні 6 вкладок, почнемо по порядку:
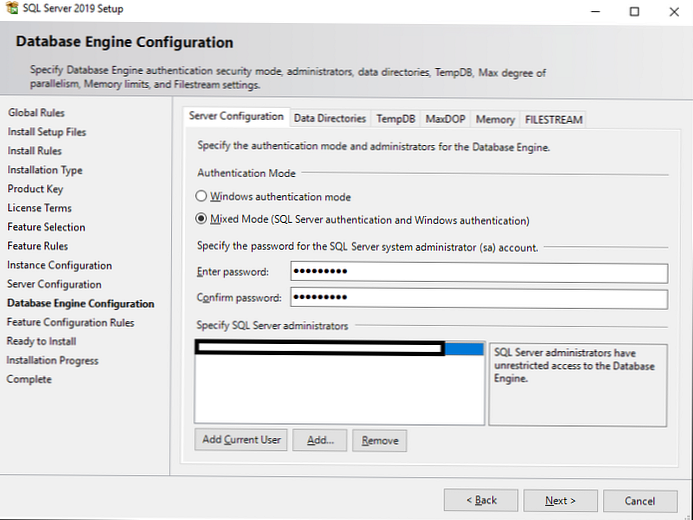
У Server Configuration ви повинні вибрати Authentication Mode і вказати аккаунт для адміністратора SQL Server'a.
У вас на вибір є 2 режиму: Windows authentication mode і Mixed mode.
- З Windows аутентифікацією авторизуватися зможуть тільки користувачі вашого домену або комп'ютера під керуванням Windows.
- У Mixed mode крім windows авторизації стане доступна авторизація за обліковими даними самого SQL Server'a.
Майкрософт рекомендує використовувати Windows Authentication як найбезпечніший, але на практиці швидше за все вам потрібно буде логінитися на сервер з інших додатків. Наприклад, написаних на java, і в такому випадку без аутентифікації SQL сервера не обійтися.
Якщо ви впевнені, що ваші користувачі будуть логінитися тільки з Windows комп'ютерів і програм, які підтримують Windows аутентифікацію, то вибирайте Windows authentication mode.
У моєму випадку я ставлю Mixed mode. У цьому режимі вам потрібно буде прописати пароль від користувача sa і вибрати Windows аккаунт, який буде володіти адміністративними правами.
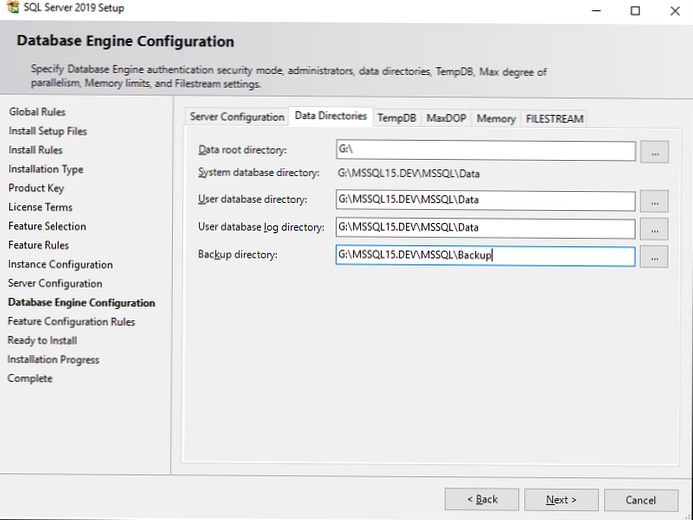
на вкладці Data Directories ви повинні вибрати каталог, в якій SQL Server буде зберігати базу даних і транзакційні логи.
Для даних найкраще виділити окремий RAID масив. Дискова підсистема критично важлива для продуктивності SQL Server'а, тому необхідно вибрати найкращий з доступних вам варіант зберігання даних, будь то NAS або локальний RAID з швидких дисків.
Доброю практикою вважається рознесення всіх директорій (системних баз даних, призначених для користувача баз даних, логів користувацьких баз даних, резервних копій) на різні сховища. Таким чином ви досягнете максимальної продуктивності від SQL Server'а на рівні роботи з зберіганням даних.
У моєму випадку я вкажу окремий диск з RAID 1 для всіх директорій.
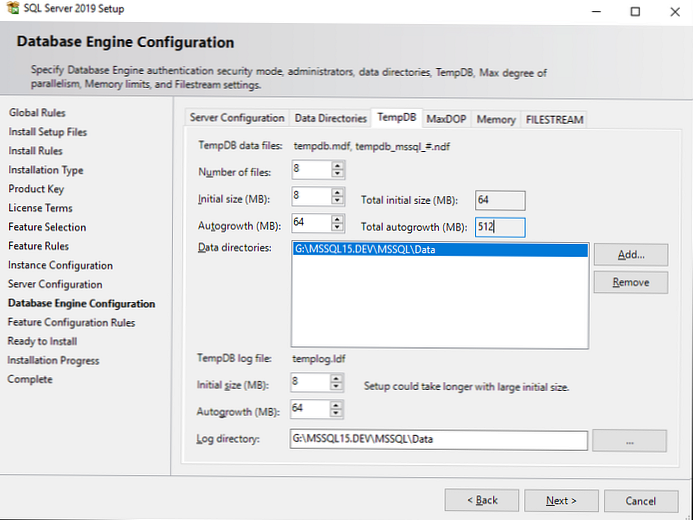
на вкладці TempDB налаштовуються параметри для бази tempdb. Її правильна конфігурація важлива для продуктивності сервера, так як ця база бере участь практично у всіх операціях з даними.
- Number of files - кількість файлів даних для tempdb. Вам потрібно вказати кількість файлів в залежності від ядер процесора. Доброю практикою вважається виставляти кількість файлів рівною кількості ядер процесора поділених на 2. Тобто на 32 ядра вашого сервера рекомендується 16 файлів. Також незалежно від кількості ядер не рекомендується ставити менше 8 файлів, це необхідно, щоб уникнути проблем, описаних тут https://support.microsoft.com/en-us/kb/2154845 .
- Initial size - початковий розмір файлів даних tempdb. При кожному перезавантаженні сервера, розмір tempdb буде скидатися до початкового розміру. Рекомендується вказувати розмір файлів даних в залежності від планованого навантаження. Якщо ви не можете спланувати майбутнє навантаження, то залиште 8 MB. Якщо ви виділите окремий масив / диск під файли tempdb (про це нижче), то найкраще буде вказати такий розмір файлів, який би повністю заповнив диск, щоб уникнути постійних операцій збільшення файлу.
- Autogrowth - крок збільшення файлів tempdb. Розмір потрібно ставити в залежності від початкового розміру. Залиште 64 МB, якщо не можете спланувати навантаження. Майте на увазі, якщо включений IFI (Instant File Initialization) то очікування блокувань на розширення файлу буде набагато менше. Не рекомендується ставити розмір кроку занадто великим, так як це викличе суттєві затримки при збільшенні розміру файлу.
- Data Directories - директорії для розміщення файлів даних tempdb. Якщо ви вкажете кілька директорій, файли будуть розміщуватися за алгоритмом Round-robin, тобто циклічно. Грубо кажучи при вказівці, наприклад, 4 директорій, файли даних розподіляться по всіх тек в рівній мірі. Доброю практикою буде додати різні дискові масиви для файлів даних.
- TempDb Log file: Initial size / Autogrowth - настройка початкового розміру і кроку збільшення файлу лога tempdb. Варто дотримуватися таких же правил, як і для файлів даних tempdb.
- Log Directory - директорія для зберігання лог файлу tempdb. Лог файл всього 1, незалежно від кількості файлів даних, вказується всього 1 директорія. Якщо є можливість, лог файлу також виділіть окремий масив.
вкладка MaxDOP.
MaxDOP це параметр SQL Server'а який відповідає за паралельне виконання запитів і відповідно ступінь паралелізму. Для того щоб SQL Server використовував всі ядра процесора для обробки паралельних планів, встановіть 0 як значення MaxDOP. Якщо з якихось причин ви хочете відключити паралельне виконання запитів, встановіть 1 в якості значення. Для максимальної продуктивності налаштуйте MaxDOP згідно з правилами в таблиці (https://go.microsoft.com/fwlink/?linkid=2084761):
| Сервер з одним вузлом NUMA | Не більше 8 логічних процесорів | Значення параметра MAXDOP не повинно перевищувати кількість логічних процесорів |
| Сервер з одним вузлом NUMA | Більше 8 логічних процесорів | Значення параметра MAXDOP має дорівнювати 8 |
| Сервер з декількома вузлами NUMA | Не більше 16 логічних процесорів на вузол NUMA | Значення параметра MAXDOP не повинно перевищувати кількість логічних процесорів на кожен вузол NUMA |
| Сервер з декількома вузлами NUMA | Більше 16 логічних процесорів на кожен вузол NUMA | Значення MAXDOP має дорівнювати половині кількості логічних процесорів на вузол NUMA зі значенням MAX, рівним 16 |
У моєму випадку я поставлю 0. Це дасть найбільшу продуктивність для виконання планів паралельних запитів, але це може викликати затримки, так як інші запити повинні будуть дочекатися завершення виконання поточного запиту, тому що все ядра процесора будуть зайняті виконанням поточного запиту.
Для "бойового" сервера я все ж рекомендую слідувати правилам з таблиці, а також ознайомитися з документацією по посиланню вище.
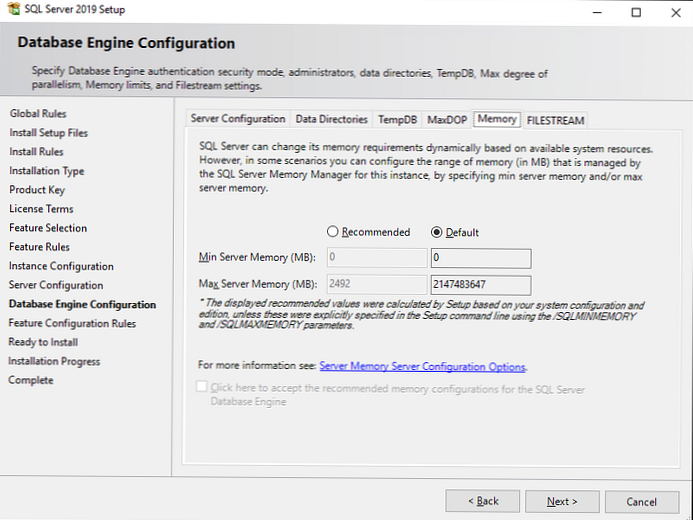
вкладка Memory - потрібно вказати мінімальний і максимальний обсяг оперативної пам'яті, який буде використовувати SQL Server. Так як спрогнозувати потрібний обсяг для сервера досить складно, рекомендується виділити SQL Server'у 80-85% від усього обсягу оперативної пам'яті сервера. Для того щоб дізнатися реальний обсяг використовуваної оперативної пам'яті, потрібно цілодобово моніторити споживання оперативної пам'яті через спеціальні DMV (Dynamic Management View) і відстежувати піки споживання RAM. Тільки з наявністю цієї інформації можна спрогнозувати реальний обсяг споживання оперативки.
Я залишу Default значення (min 0 і max 2147483647 MB).
Вкладка FILESTREAM - включення технології FILESTREAM. Вона дозволяє зберігати бінарні файли на файлової системи і забезпечує доступ до них через SQL. Якщо ви не впевнені, що хочете працювати з бінарними даними на рівні SQL, то тоді залиште FILESTREAM вимкненим.
Крок Feature Configuration Rules пройде автоматично. Ознайомтеся зі зведенням в Ready to Install і тисніть Install.
На цьому базова установка SQL Server 2019 Enterprise завершена. У наступній статті ми подивимося на основні способи аналізу продуктивності і проблем в SQL Server.
Примітка. На старіших версіях (SQL Server 2014 року, 2016) деяких вкладок і параметрів може не бути.






{kind=link}