

Одним із наріжних елементів технології забезпечення ідентифікації та безпеки - Dynamic Access Control (Динамічного контролю доступу) в Windows Server 2012, є функціонал File Classification Infrastructure (FCI - Інфраструктури класифікації файлів). FCI використовується на файлових серверах організації і надає можливість створювати нові властивості і атрибути(File-classification properties) для класифікації по ним файлів. FCI дозволяє в автоматично режимі класифікувати файли відповідно до вмісту файлу або каталогом, в якому вони знаходиться; здійснювати управління файлами (наприклад, термін протягом якого можливий доступ до файлу); генерувати звіти, що показують розподіл класифікаційних властивостей на файлових сервері. Файли на підставі ключових слів або патернів можуть в автоматичному режимі класифікуватися, наприклад, як конфіденційні або містить персональні дані. Однак користувач (власник) без використання FCI може і вручну класифікувати файли.
FCI - це елемент Dynamic Access Control, який класифікує файли, привласнюючи їм теги, від яких залежить застосування політик DAC.
вперше технологія File Classification Infrastructure з'явилася в Windows Server 2008 R2. Які ж можливості вона надавала? За допомогою FCI можливо реалізувати різні сценарії обробки документів в файлових сховищах (в т.ч. містять конфіденційну інформацію): збір, шифрування, перенесення, архівування, відправку по маршруту і видалення файлів. За допомогою FCI можна, наприклад, реалізувати сценарій, що дозволяє грунтуючись на класифікації файлів, автоматичного переміщення файли з дорогих сховищ в більш дешеві і повільні, або наприклад, автоматично робити файли недоступними через певний час.
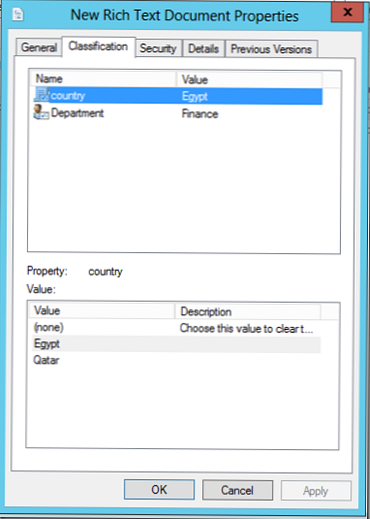
На скріншоті нижче показаний приклад файлу, який класифікований як відноситься до країни Єгипет і відділу "Finance". Атрибути класифікації можуть бути абсолютно будь-яким: наприклад, пріоритет, конфіденційність, місце розташування, організація і т.д.
Як класифікувати файл або каталог вручну
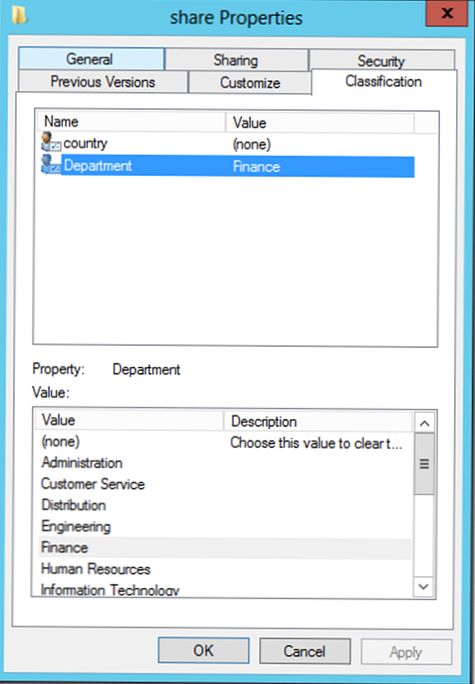
Файли і каталоги можна класифікувати вручну, відкривши вікно властивостей об'єкта і вибравши вкладку "Classification". У нашому прикладі зі списку зумовлених значень можна вибрати інші значення для атрибутів country і Department.
автоматична класифікація
Для настройки автоматичної класифікації об'єктів в Windows Server 2012 необхідно з допомогти консолі Server Manager встановити роль File Server (Файлового сервера).
встановивши компонент File Server Resource Manager (FSRM), відкрийте відповідну MMC консоль і серед знайомих груп Quota, File Screening, File Management ви побачите новий підрозділ Classification Management (Управління класифікацією), що складається в свою чергу з двох підрозділів:
- Classification Properties - служить для створення атрибутів класифікації (в нашому прикладі це атрибути country і Department, що мають статус глобальних, тому що вони опубліковані в AD)
- Classification Rules - правила автоматичної класифікації

Щоб налаштувати автоматичну класифікацію документів, потрібно створити правило класифікації.
Одним із способів організації автоматичної класифікації файлів на підставі місця розташування - властивість класифікації - FolderUsage. Це зумовлене властивість, що зберігається в розділі Classification Properties. За замовчуванням, в ньому визначені 4 типи даних:
- Дані додатків - Application data
- Резервні копії - Backup Data
- Групові дані - Group Data
- Файли користувачів - User Files
Тут же можна створити власні типи даних.
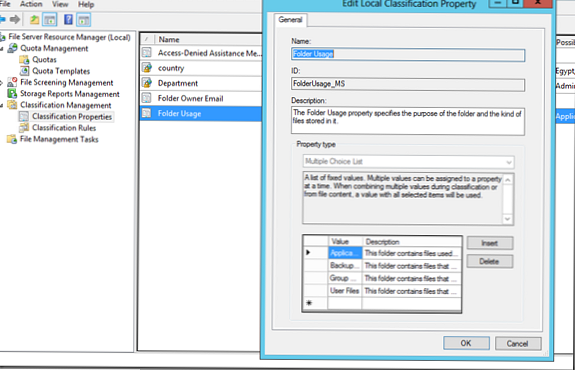
Створимо тут власні типи папок для фінансового (Financial) і інженерного відділу (Engineering) .Потім необхідно визначити які файли до якого відділу (типу даних) віднести. Для цього клацніть по порожньому місці консолі FSRM в розділі ClassificationProperties і виберіть пункт SetFolderManagementProperties
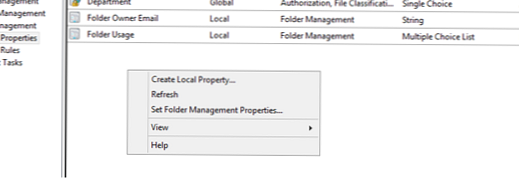
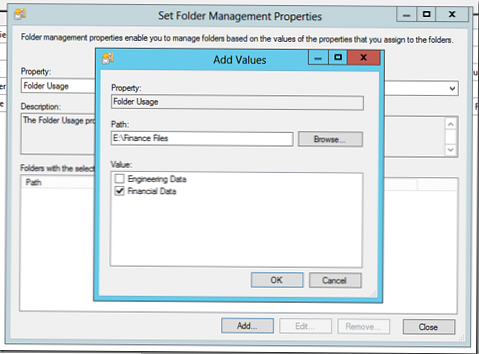
Виберіть властивість FolderUsage і вкажіть папки, які будуть використовуватися кожним департаментом, або містять певний тип даних. Однак слід розуміти, що в даному випадку налаштовувати не класифікація файлів (ми будемо налаштовувати її пізніше), ми визначимо приналежність папок, яку задіємо в класифікують правилі
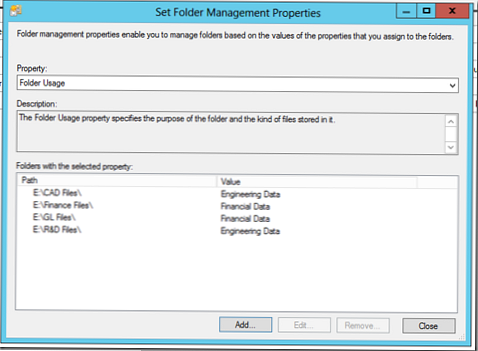
Ми налаштували так:
Створимо правило класифікації даних
Прийшов час в розділі ClassificationRules створити нове правило (контекстне меню Create Classification Rule):
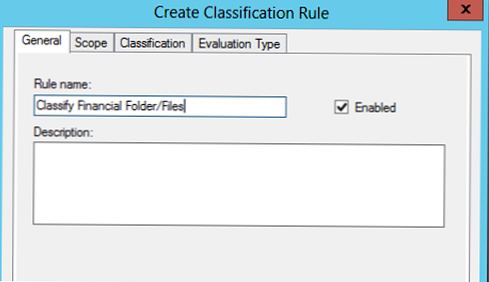
Вкажіть ім'я правило (ми створюємо правило класифікації файлів як належать фінансовому департаменту).
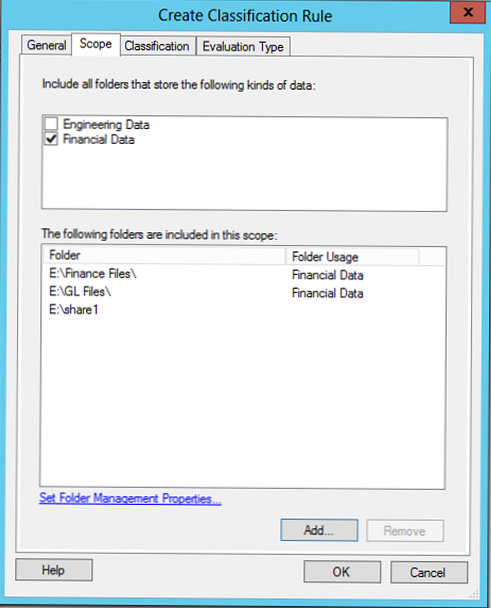
на вкладці Scope вказуємо каталоги, які необхідно враховувати при проведенні класифікації, виберемо створене раніше правило FinancialData (Автоматично додає всі обрані раніше папки), можна також додати каталоги вручну (в прикладі це E: \ share1).
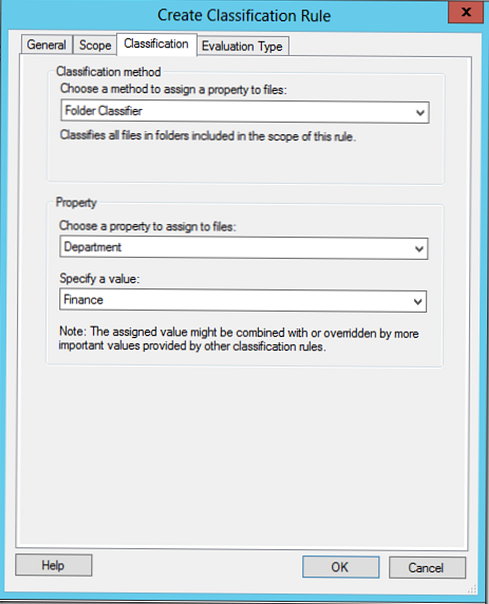
на вкладці Classification можна вибрати один з двох методів класифікації:
- Folder Classification - класифікація на підставі каталогів (атрибути застосовуються до всіх файлів каталогу)
- Content classification - класифікація за вмістом файлів. У цьому трапляється по всіх файлів в каталозі здійснюється пошук за ключовими словами, паттернам або регулярними виразами (номера проектів, кредитних карт, ідентифікатори відділів і т.д.).
На скріншоті вказано правило класифікації на підставі каталогів, правило класифікації по вмісту буде розглянуто нижче.
на вкладці Evaluation Type вказується порядок застосування та повторного застосування правил класифікації до файлів. У прикладі нижче ми вказали, що система може перезаписувати поточну класифікацію, тим самим ми гарантуємо, що призначена для користувача класифікація буде перевизначена корпоративним правилом.

У наступному правили класифікації ми створимо правило класифікації на основі вмісту файлу:
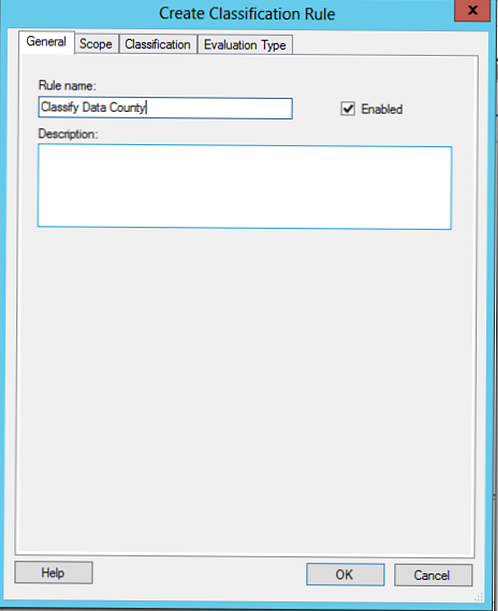
В даному правилі здійснюється класифікація даних по країні, тому ми додамо в нього каталоги та інженерного і фінансового департаменту.
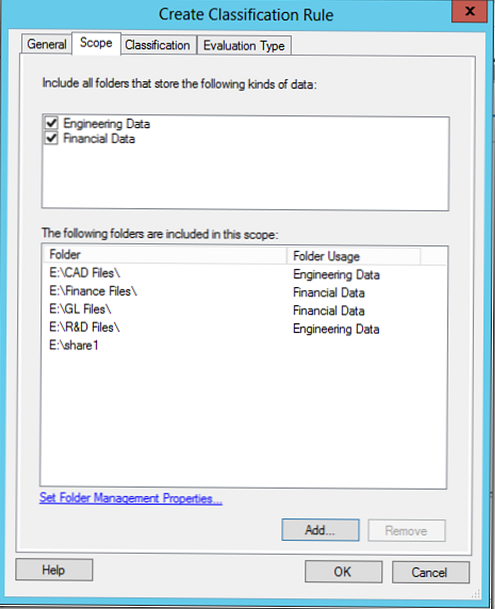
В даному правилі класифікації на основі вмісту файлу, ми спробуємо класифікувати дані, що відносяться до країни Egypt.
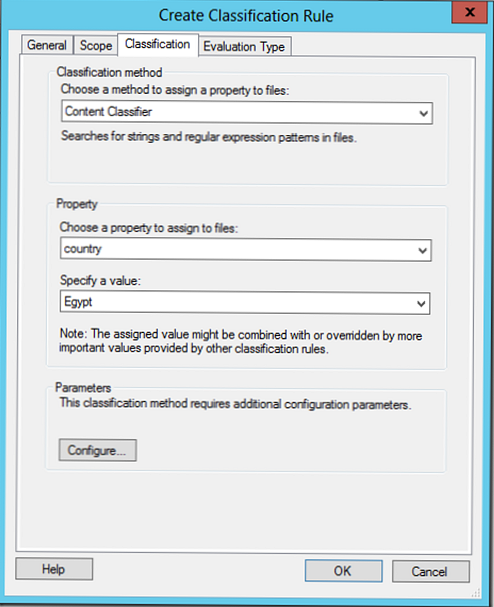
У розділі Parameters виберіть Configure. У вікні можна реалізувати пошук на підставі регулярних виразів, рядки або чутливі до регістру рядки.
За допомогою регулярних виразів можна здійснювати пошук в текстових документах (в тому числі файлу tiff) за різними критеріями, наприклад:
- Наявність коренів в слові, не звертаючи уваги на відмінки і суфікси
- Наявність слів або словосполучень в довільному порядку
- Наявність даних в певному форматі, наприклад номерів кредиток, телефонів, даних паспортів чи адрес електронної пошти
- Умови зустрічі певної кількості зустрічі шуканих даних в файлі (наприклад, не менше 3 номерів кредитних карт, або телефонів)
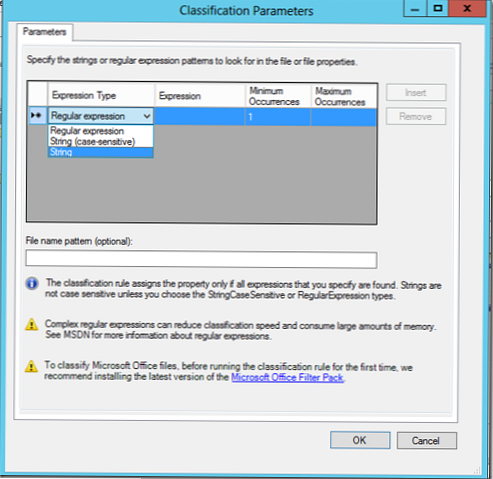
У нашому прикладі, ми здійснимо пошук документів за ключовим словом Egypt, і в разі виявлення файл повинен класифікуватися цим правилом (можна вказати мінімально і максимально необхідну кількість входжень ключового слова в документ).
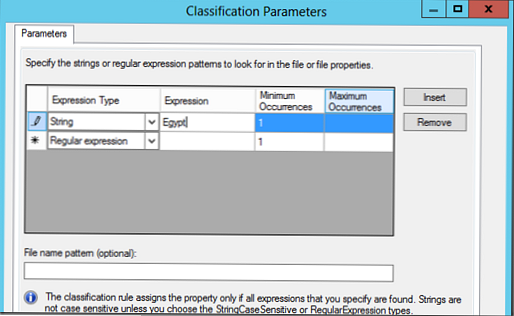
Отже, ми створили два правила класифікації:
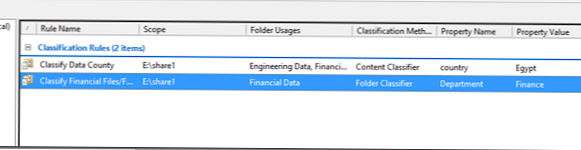
Спробуємо тепер запустити автоматичну класифікацію файлів. Нехай у нас є 2 файли, один з яких містить слово Egypt, а другий - ні. Ці файли поміщені в Каталоги "Financial Files" і "R & D files", як ви бачите на даний момент вони ніяк не класифікований.
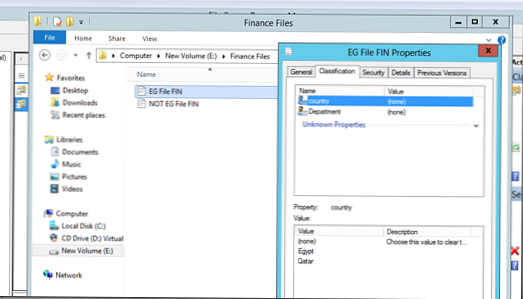
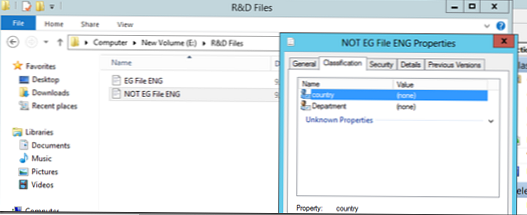
Запустимо наші класифікують правила (Run Classification With All Rules):
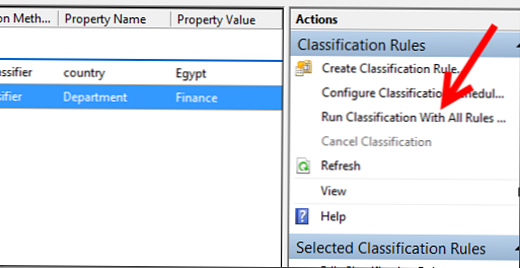
З результатом роботи правил можна познайомиться в звітах в звітах.

Як ви бачите, все відпрацювало правильно, файлам з ключовим словом присвоєна правильна країна, а всього вмісту каталогу фінансового відділу атрибут Finance.
На даному етапі ніяких операцій з класифікуються файлами виконано не було, вони були просто відзначені потрібними нам атрибутами. Надалі на підставі класифікації файлів з ними можна виконати різні операції, зокрема зашифрувати файли за допомогою AD RMS (приклад використання описаний в статті Шифрування файлів за допомогою AD RMS на базі інфраструктури класифікація файлів Windows Server 2012), або керувати доступом до них за допомогою Windows Server 2012 Dynamic Access Control. Ці аспекти ми розглянемо в наступних статтях серії.

{kind=link}